This document provides an intuitive introduction and guide to the Neuroimaging Data Model (NIDM) for software
interoperability. NIDM defines a core vocabulary that extends the PROV Data Model for provenance with terms
that capture information about neuroimaging research, from data acquisition to analysis and results. This primer
explains the fundamental NIDM concepts and provides examples of its use. The primer is intended as a
starting point for neuroimaging scientists or developers interested in using or creating apps with NIDM.
Overview
This section provides an overview of the NIDM Family of Documents and suggestions to the neuroimaging community
for implementing these standards to support data sharing activities, as well as in reporting issues or comments.
NIDM Family of Documents
This document is part of the NIDM Family of Documents, a set of documents defining various aspects of
neuroimaging research that are necessary to achieve the vision of inter-operable interchange of information in
heterogeneous environments such as the Web, research consortia, and laboratories. A list of current NIDM documents and the latest revision of this specification can be
found in the NIDM
specification index. These documents are listed below.
NIDM-OVERVIEW (Draft), an overview of the
NIDM Specification Suite [[!nidm-overview]];
NIDM-PRIMER (Draft), a primer for the NIDM
(this document);
NIDM-DATASET-DESCRIPTOR (Draft), the
NIDM Dataset Descriptor is a high level description of neuroimaging data modeled using NIDM
[[!nidm-dataset-descriptor]];
NIDM-EXPERIMENT (Draft), a data model for
describing the organization of raw neuroimaging experiment data [[!nidm-experiment]];
NIDM-RESULTS (Draft), a data model for
describing the results of neuroimaging analyses.[[!nidm-results]].
Implementations Encouraged
The NIDM Working Group encourages implementation of the specifications overviewed in this document. Work on
this document by the NIDM Working Group is ongoing, errors and suggestions may be reported in the issue tracker and these may be addressed in future revisions.
Please Send Comments
This document was published by the NIDM Working Group as a Working Draft. If you wish to make comments
regarding this document, please report using the NIDM issue
tracker. You can also ask questions at Neurostars Q&A. All comments
are welcome.
Introduction
This primer document provides an accessible introduction to the Neuroimaging Data Model (NIDM) for data
sharing at Web scale. NIDM is an extensible framework for community driven development of metadata standards
that captures a broad spectrum of research information, particularly data provenance. The provenance of a
given piece of neuroimaging data represents its origin, which can facilitate reproducible research by capturing
a description of how data was processed. The NIDM Family of Documents includes specifications that define
recommendations for how to model neuroimaging research information across several stages of the research
process, referred to as NIDM Components.
As a specification for neuroimaging data exchange, NIDM Components address specific information needs for the
neuroimaging community. Different NIDM users or developers may have different perspectives on the types of
neuroimaging data they would like to exchange.
One perspective may focus on representing high-level information about a neuroimaging database. For example,
an XNAT database provider may want to provide an standard description of the projects it contains that is
interoperable with a similar description of a COINS or HID database. This dataset descriptor would allow a
service to aggregate dataset descriptions that could then be interrogated at a finer level of detail.
A second focus may be to query for low-level details about participant demographics and DICOM metadata (e.g.,
TR or slice thickness) stored in an XNAT database. For example, a user may identify a dataset of interest in
the previous example and want to retrieve the download links for structural scans from normal controls over
18 years of age.
A third perspective might be interested in the results of a statistical analysis. For example, an author
may have published their dataset with OpenfMRI and included their results from a task-based fMRI experiment.
A researcher may be interested in including this dataset in a meta-analysis, and can query its NIDM
representation to retrieve all the necessary pieces of information.
This primer document aims to ease the adoption of the NIDM specifications by providing:
A high-level explanation of how NIDM models different types of neuroimaging information.
A simple example explaining how information from a neuroimaging database can be modeled as an extension of
PROV and include a number of useful vocabularies as annotations on the model.
Intuitive overview of NIDM
This section provides an explanation of the main concepts in NIDM, which are extensions of PROV. As this
document is meant as a starting point, refer to PROV and the NIDM specification for a given Component for
detailed recommendations.
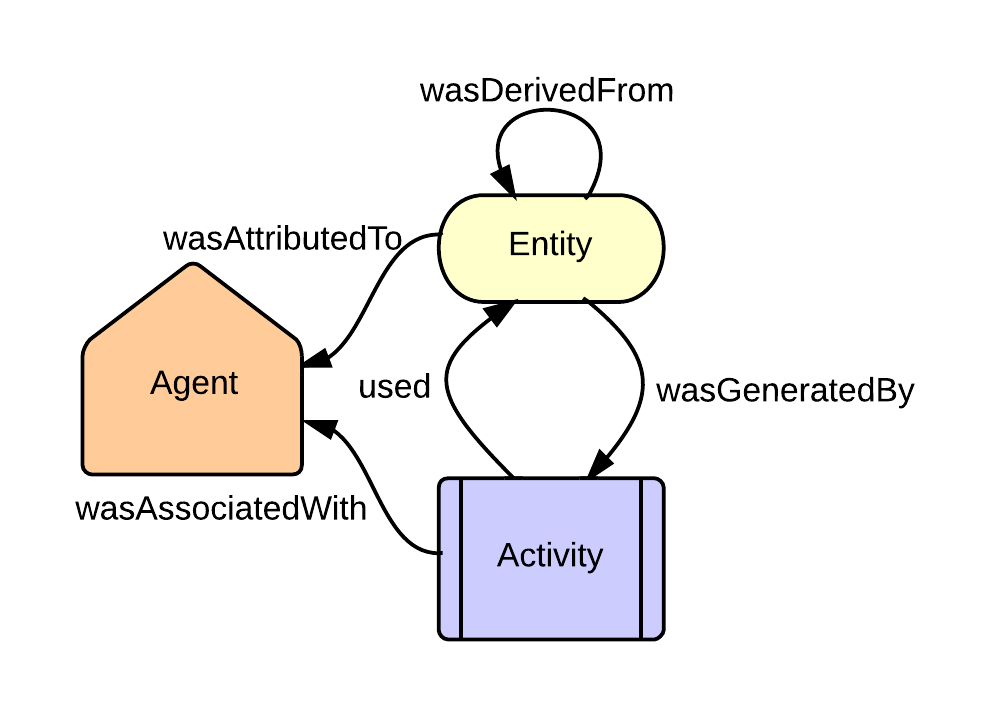
A central theme in NIDM is to view all the information produced during the course of an investigation in the
context of provenance, which is accomplished by building NIDM as an extension of the W3C PROV recommendations
(Figure 1). PROV defines a core set of high-level structures for capturing provenance information that
bolsters trust in how a given piece of information was generated. The PROV specification details three core
objects that are used to describe provenance, which are
Entities, Agents, and
Activities. These core objects are related to each
other with a set of defined relations, as highlighted in the figure below.
Entities are used to capture information that tends to persist over time, for example a dataset or spreadsheet
file, which can be modified of derived from other entities. For an Entity, like a file, to be created, an
Activity is needed that describes how the Entity came into existence, and an Agent is needed to describe who
(e.g., a person) or what (e.g., an organization or software) is responsible for generating an Entity. The
binding of these three objects provides the structure needed to trust how and who some file, dataset, or
analysis was created.
A central theme in NIDM is to view all the information produced during the course of an investigation in the
context of provenance, which is accomplished by building NIDM as an extension of the W3C PROV recommendations.
In addition to PROV, NIDM adopts a number of metadata vocabularies that are actively being used in the broader
Web community (e.g., Dublin Core, FOAF, VoID, and DCAT). By adopting existing vocabularies and harmonizing
our efforts with similar groups developing biomedical metadata standards (e.g., W3C Health Care and Life
Sciences Interest Group, ISA Commons), NIDM is able to maintain a common description of high-level concepts
that are shared across biomedical domains (e.g., project descriptions and participant demographics) while
providing additional specificity for the neuroimaging domain. This additional specificity is captured in
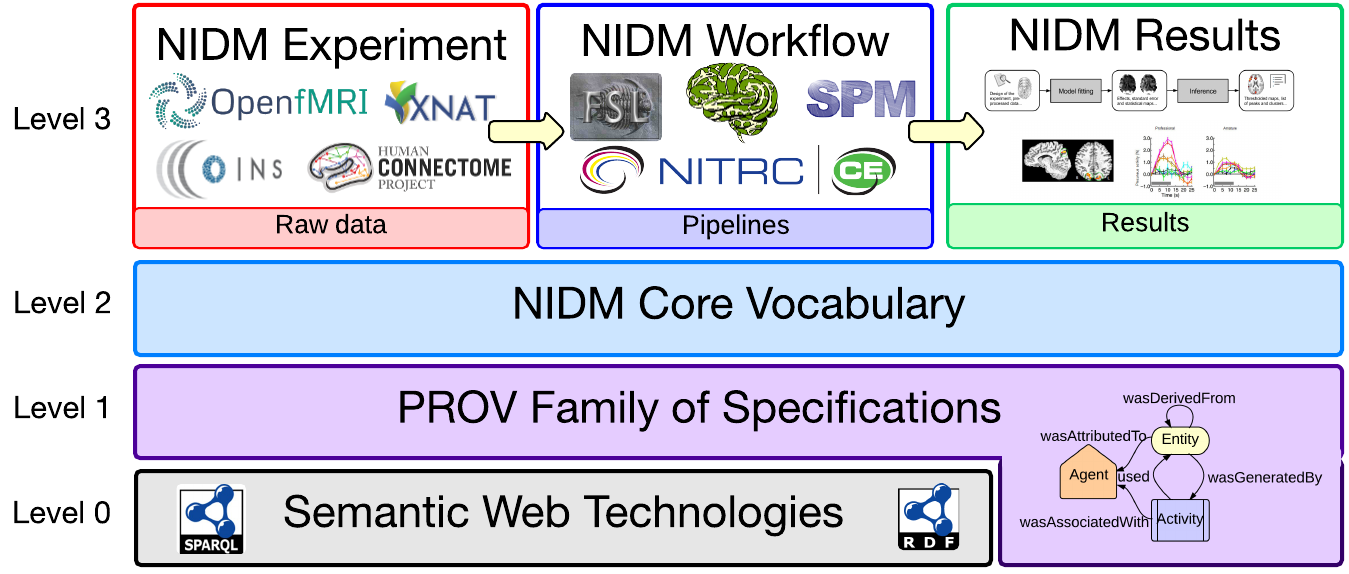
layers by building a NIDM Core vocabulary, based on PROV, that is then extended to model specific types of
information, referred to as NIDM Components, and then linked together using a high-level dataset descriptor
(Figure 2).
The NIDM Component Layer Cake. Each level indicates a set of technologies and/or vocabularies that are
“imported” into the next level. (Inspired by the
Semantic Web Layer Cake)
Dataset Descriptor Component
The NIDM Dataset Descriptor Component is modeled after the efforts of the Health Care and Life Sciences
(HCLS) Interest Group at the W3C. HCLS aims to provide a generic dataset descriptor recommendation that
captures a general set of metadata that is applicable across domains. NIDM adopts the HCLS approach and
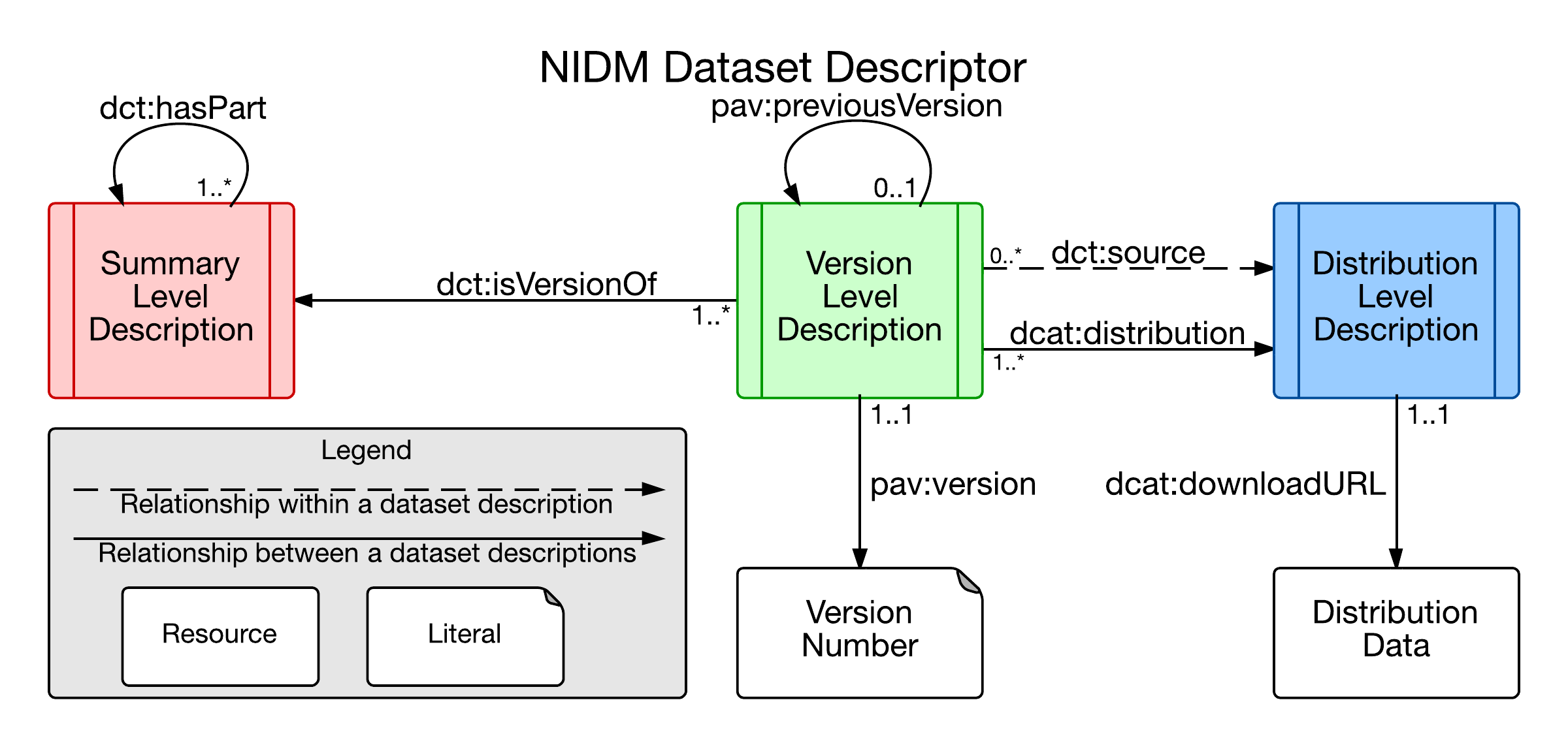
extends it by providing an additional set of recommendations that are specific to neuroimaging. The HCLS
Dataset Descriptors are organized into three levels – Summary, Version, and Distribution (Figure 3). The
Summary-level is focused on information that does not change over the course of a project, while the
Version-level captures changes that are specific to a given data release. The Distribution-level is
intended to inform the consumer with links to where specific datasets can be accessed, which may come in
one or more forms (e.g., relational database, tarball, or RDF). In the case of RDF, datasets can be
described using the VoiD vocabulary (www.w3.org/TR/void/), which is the recommended approach with NIDM,
as it allows each NIDM Component for a given project to be described independently and linked appropriately
using URIs.
NIDM Dataset Descriptor. Summary-level descriptions provide information that does not change between
difference versions or releases of a dataset. Version-level descriptions provide information that is
specific to a given version. Distribution-level descriptors captures information that is specific to
a given format or serialisation of a dataset. Figure adapted from the
HCLS Dataset Description Levels.
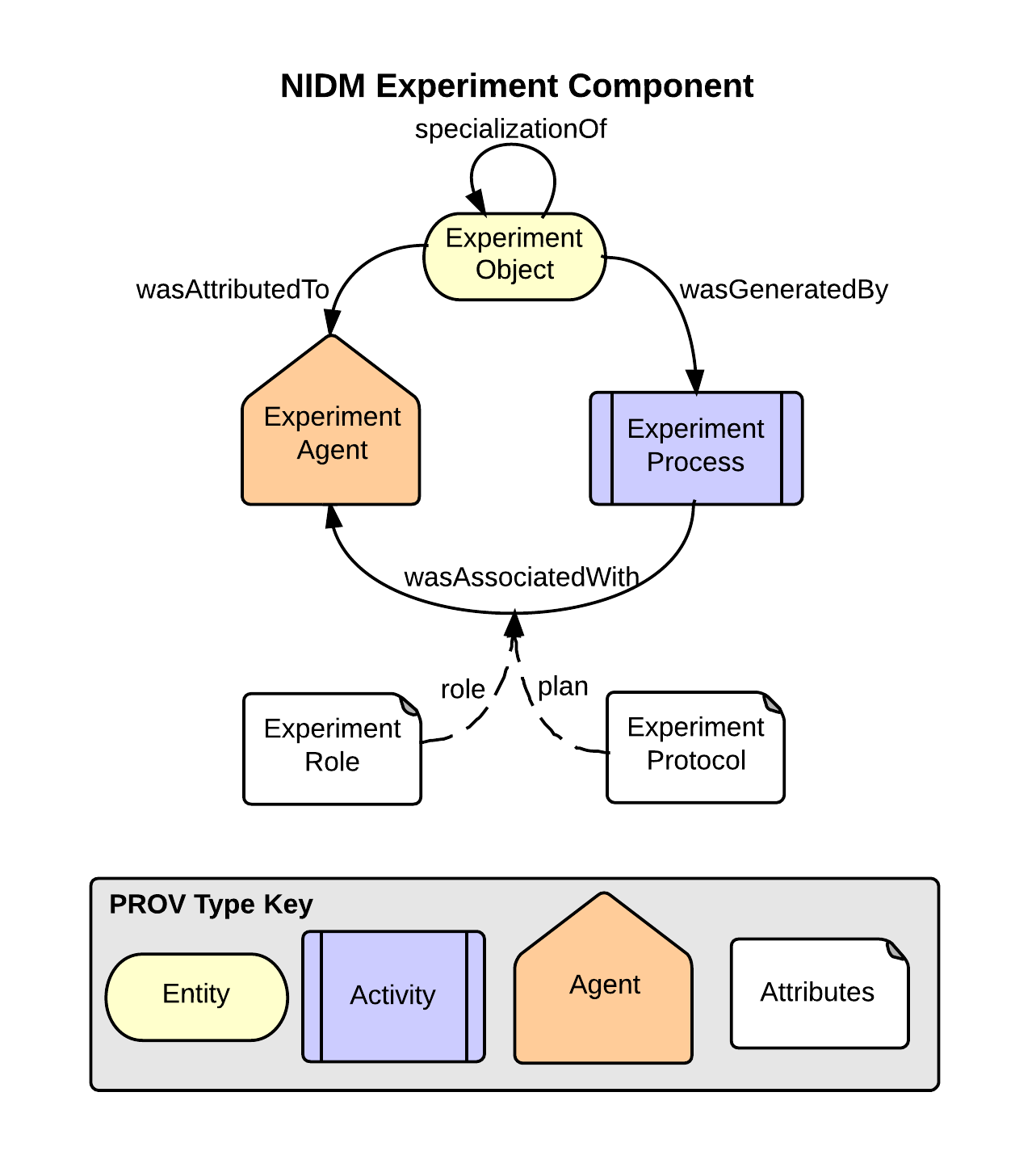
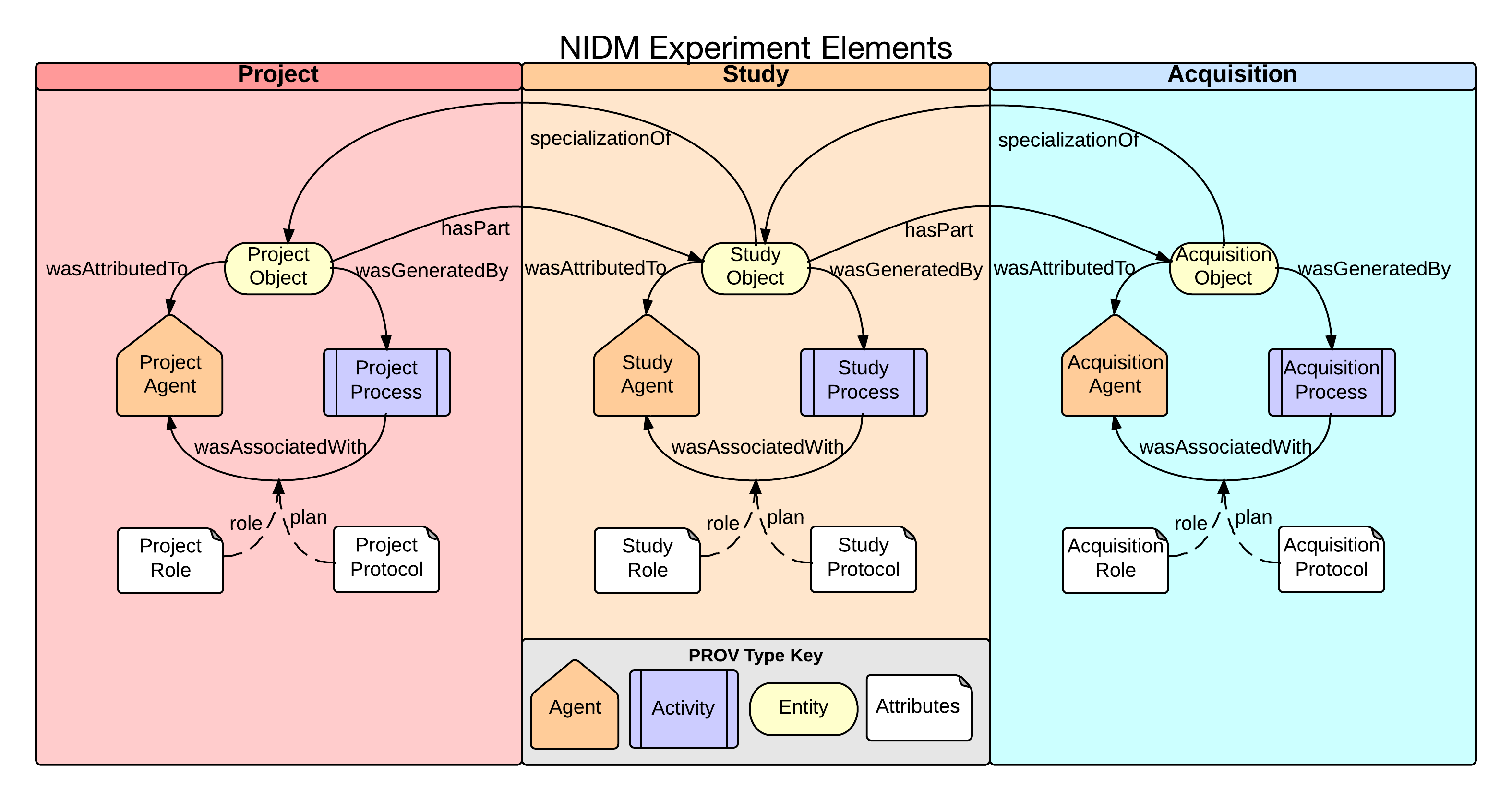
Experiment Component
NIDM Experiment Component.
NIDM Experiment Elements.
Workflow Component
The NIDM Workflow Component focus group is just beginning to work on an object model for capturing workflow provenance. We encourage those interested in participating to contact the NIDM google group for further information. There has been work
on two preliminary implementations of provenance using NIDM, one using the Nypipe workflow system and the other the SPM batch processing system.
An example of a Nipype workflow for extracting the brain from a structural MRI scan can be found at BET workflow.
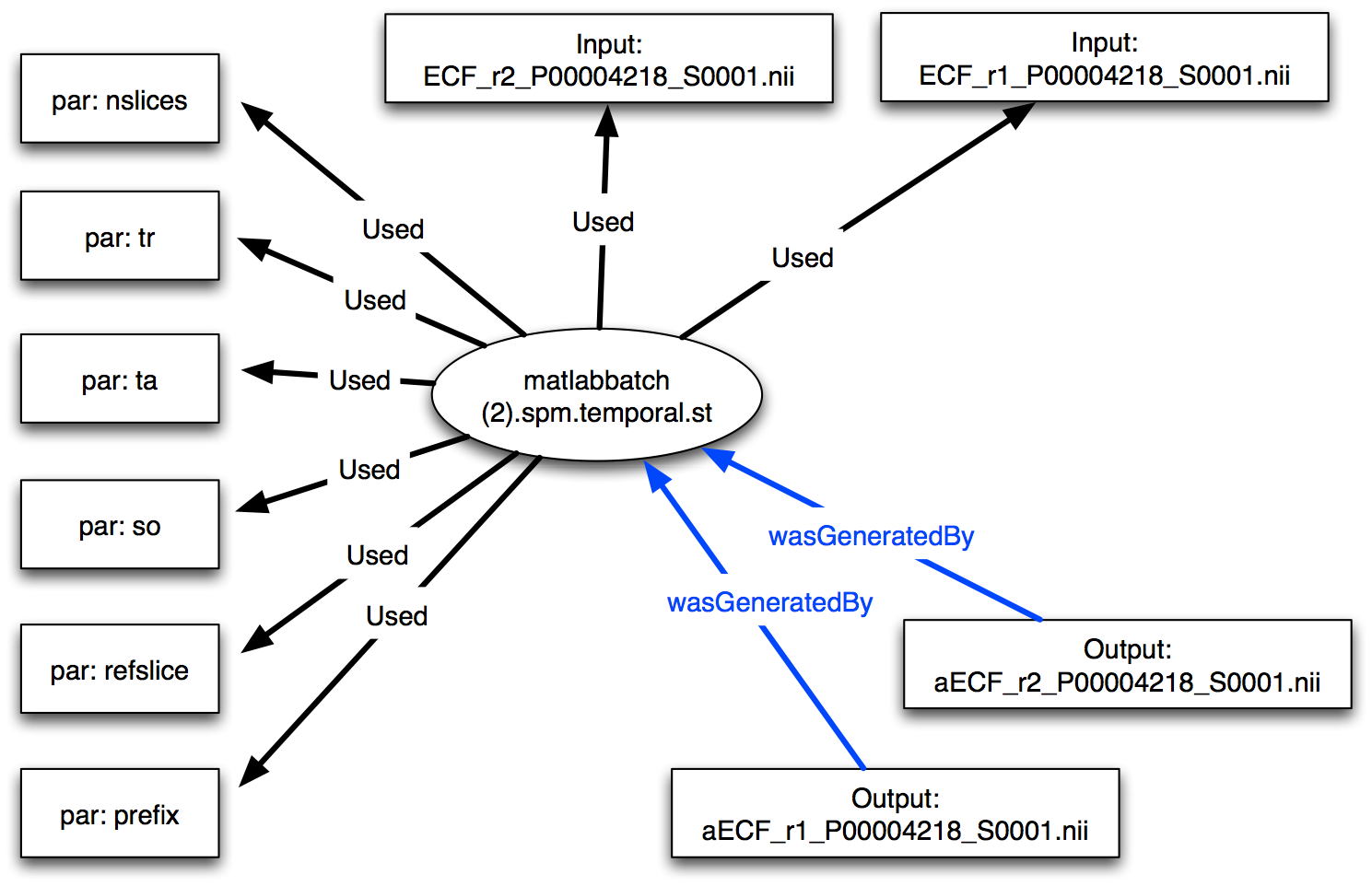
An preliminary example encoding a batch execution of slice timing correction using the Statistical Parametric Mapping software is showing in the figure 6.
NIDM encoding of a slice timing correction workflow in the SPM software ([[!KEATORNI13]]).
Results Component
Designing Your NIDM Object Models - A Brief Tutorial
In this section we give a brief tutorial on modeling your data with NIDM. This will serve as a good starting point
and contains further information about choosing vocabularies and documenting your object models.
Conceptial Model
The first step in modeling your data is to create a conceptual graph of the objects needed to represent the data you will instantiate into a NIDM object model. Here we will use a particularly simple example. We will start with
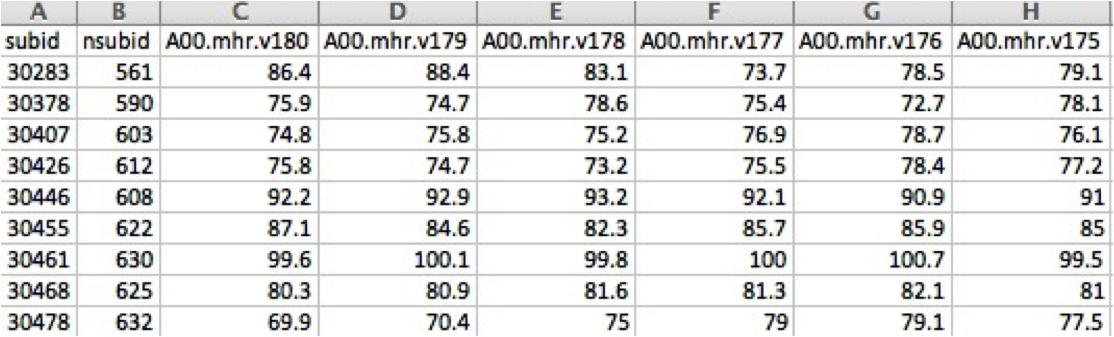
an Excel spreadsheet containing a time series of maternal heart rate measurements sampled each second for 180 seconds during pregnancy. This data was collected at the University of California, Irvine (UCI) as part of the UCI Conte Center. First, let's have a look at a subset of the Excel spreadsheet.
Maternal heart rate measurements data file.
Columns A and B are the subject identifiers for the mother and fetus respectively. Columns C-H are the heart rate measurements over time. Note, the columns have been truncated to only show the last 6 seconds of the 180 second acquisition.
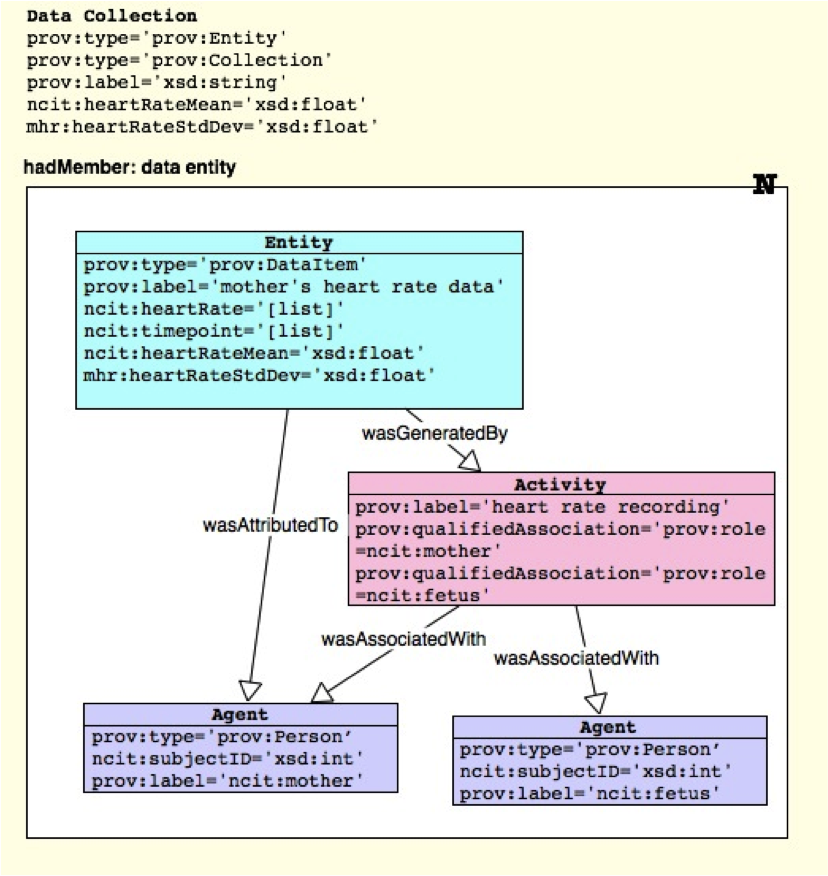
Now we can create a conceptual model of this spreadsheet. In this step we decide on how to represent the data as a graph using the PROV-DM core objects: agents, entities, and activities and what relationships needed to connect the
information. We create an entity for the heart rate measurements, an activity for the process of measuring the data, and 2 agents, one for the mother whom the heart rate measurements are prov:wasAttributedTo and one of the fetus which the heart rate measurements are prov:wasAssociatedWith.
Graph describing the heart rate data as entities, agents, and activities.
Attributes Sets
Next, we decide on the attributes needed to describe the entities, agents, and activities we created in our conceptual model. Here we can create as many attributes as necessary but we should be parsimonious whenever possible. Too many attributes can make your NIDM object model overly complex. In this example we have chosen to add the attributes ncit:heartRate, ncit:timepoint, ncit:heatRateMean, and mhr:heartRateStdDev to the heart rate entity. The prov:type and prov:label attributes are standard attributes in PROV-DM which are typically added to most entities and agents. The format of the attributes is described in the section Vocabularies and Terms Selections section. For the agents we have added the ncit:subjectID attribute to capture the data in Columns A and B of the spreadsheet. Lastly, we have added some associations in the activity to associate the activity with the two agents.
Vocabularies and Terms Selections
In order to give our representation semantic meaning we follow the conventions used in the Resource Descripition Framework (RDF) W3C recommendation such that each attribute is formated as a Internation Resource Identifier (IRI). IRIs, a generalization of Uniform Resource Identifiers (URIs) are dereferencable objects that can be found on the web to give semantic meaning to the attribute. For example, in the heart rate entity we chose the ncit:heartRate IRI. This IRI is formed using the NCIT namespace and the heartRate term within that namespace. At the begining of any NIDM serialisation of this heart rate model the NCIT namespace IRI is defined and with the term creates a deferencable definition for the attribute ncit:heartRate. It is critical to make sure the namespaces and terms you use in your models are available and persistent on the web. By following this convention instatiations of your object model are self documenting. Anyone who receives a document can make sense of the attributes and objects defined therein. In the event a term you need for your model is not defined in an existing terminology you can define you own terms but they should be available on the web.
Instantiating Your Object Model
Once you've defined your object model by specifying the objects, relationships, and attributes, it's time to apply your object model to your data. Typically one writes a parser to reformat the input data into a NIDM serialisation. Typical serialisation formats include PROV-N (the provenance notation),Turtle (Terse RDF Triple Language), JSON-LD (Java Serial Object Notation for Linked Data), and RDF-XML (Resource Description Framework XML Syntax). In Example 1 we show the Turtle syntax of the heart rate data entity for ncit:subjectID 30564.
To make writing NIDM files easier the working group has been using the ProvToolbox Java library from Luc Moreau or the PROV Python library from Trung Dong. The RDFLib has also been used by the group for efficiently working with NIDM documents in Python.
Documenting Your Object Model
To document your object model we suggest using the ReSpec javascript library. It is a simple way to make well-organized descriptions of your models and has been used for all the NIDM specs. We have included a template to make the specification writing process easier for you. The template can be downloaded and edited in any text editing program. We have included identifiers formatted with the text "[** " to indicate where the NIDM working group suggests you add information relevant to your object model. We have further added comments ubove these identifiers indexing the section in the ReSpec user manual that describes the intention of this information. The ReSpec user manual is an excellent reference for writing specifications.
Additional Information
We would also like to refer the interested reader to complementary sources of information: